
In this article, we will compare Haystack and LangChain, and how both empower Large language models(LLM). We will talk about what they do individually, what they do differently, and what tasks they are good at.
This article will be a long read explaining concepts and code examples, so if you’d like a summary of the discussed concepts, see the table below.
| Features | LangChain Support | Haystack Support |
| LLM Support | OpenAI, Cohere, AI21, HuggingFace, etc | OpenAI, Cohere, AI21, HuggingFace, etc |
| Prompt Templates and Engineering | PromptTemplates, Custom templates, Prompt Serialization, Selectors, Partial Prompts | PromptNode, PromptTemplates |
| Process orchestration | Chains | Pipelines & Ready-made pipelines |
| Data Fetching & Preprocessing | Document Loader, Text Splitting, Embeddings, CombineDocuments Chains | Document Loader, Text Splitting, Embeddings, CombineDocuments Chains |
| Document Stores | Chroma, FAISS, Elastic Search, Milvus, Pinecone, Qdrant, and Weaviate | Elasticsearch, FAISS, In Memory, Milvus, OpenSearch, Pinecone, SQL and Weaviate |
| Information Retrieval (Semantic Search & Question Answering) | Fetching Data & Augmenting | Reader, Retriever, Ranker, and QuestionGenerator |
| Deployment | No REST API | REST API |
| Agents & Memory | Agents to perform actions Memory classes | Working on adding Agents to components. |
| GPU | DeepInfra Integration | Enables GPU Acceleration |
| Other features | Generic utilities e.g Python REPL, Web search API, Requests library, SearxNG Search API, etc. Evaluation | Generative Pseudo Labelling, Evaluation |
| Use Cases | Completion, Summarization, Question-Answering, Conversational AI, Data Augmented Generation | Completion, Summarization, Semantic Search, Question-Answering, Conversational AI, Data Augmented Generation, Annotation |
Introduction – LLMs are limited
We have seen many applications in NLP, especially those focused on using Large Language Models(LLMs) to perform different tasks. LLMs are excellent at performing certain tasks such as content generation, text classification, summarization, etc. An example is OpenAI’s ChatGPT – whose release took the world by storm. As impressive as LLMs are at certain tasks, they can fall short in various areas.
The Limitations
1. LLMs aren’t up to date on current events
Let’s take a look at this example.
Navigate to ChatGPT playground, and let’s ask the question – “What is today’s weather in degrees celsius ?”
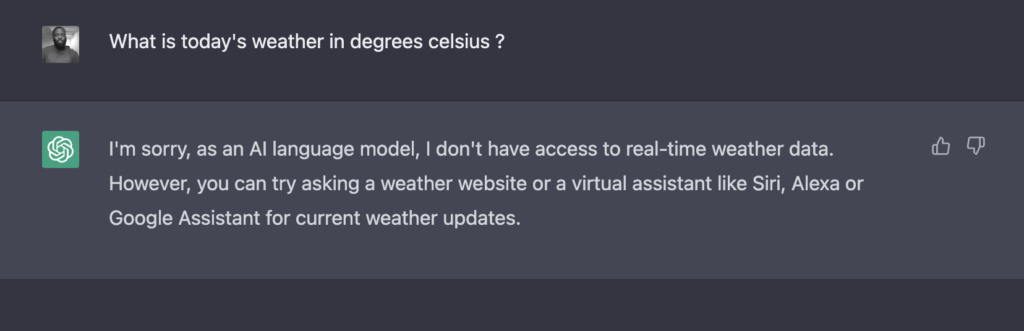
LLMs can only attempt to provide answers based on the data provided to the model at training. Therefore, any current events or more recent data following the training of the model will be excluded or won’t get answers.
Here is another example;
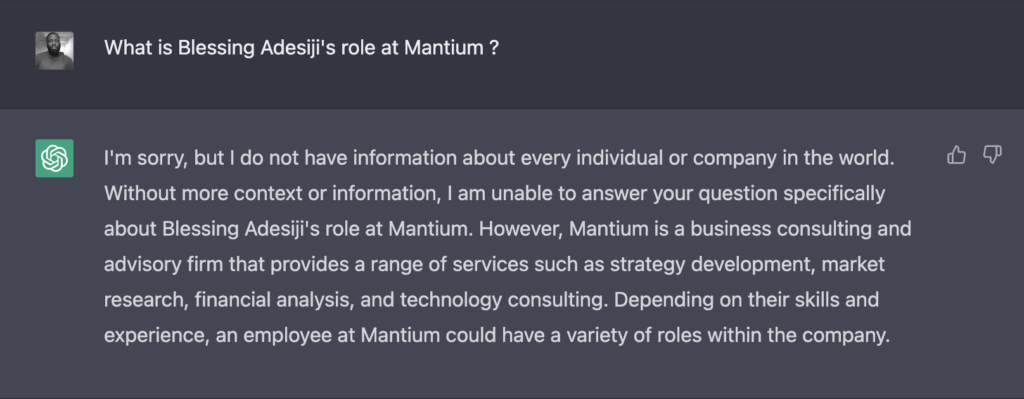
Here we can see again that LLMs do not have access to current or specific information that the model wasn’t trained with. Since ChatGPT had no knowledge about Mantium’s knowledge management system, it couldn’t correctly answer the question.
Notice the generated answer is believable but incorrect? We refer to this as hallucinating as it provides a believable but irrelevant and misleading answer.
Hallucination is when LLM – in this case, ChatGPT – generates an output that is irrelevant, misleading, and not supported by the original input.
2. LLMs can’t act to perform actions.
LLMs can’t act to perform specific actions requiring them to complete a task. For example, ChatGPT can’t initiate a web search to query the internet for current weather updates in the example above. It can’t initiate a database query against a web service or check a knowledge management system to answer specific questions. In the case of the second example, it would have been nice if an action could be triggered to search through Mantium’s knowledge management system.
There are existing tools such as LangChain and Haystack that address these limitations. Let’s dive into the article and see how both tools attempt to solve these problems.
LangChain
What is LangChain ?
Just like the name sounds – Lang, Chain means that we can chain together LLMs to build applications through composability. LangChain was created in October 2022 to build a modular and flexible framework for developing AI-native applications.
The framework provides modules for building language model applications. You can use modules to develop applications or combine them to achieve a much more complex use case. Think of modules as the building blocks that you can put together to build robust language applications.
The following section will explain each module with examples of how they work individually.
LLMs & Prompts.
This is the core building block of LangChain. The LLM class is the most fundamental building block for interacting with LLMs from different providers. There is support for about 13 LLM providers and access to interact with models hosted with your own compute.
The way to use LLMs in LangChain is to generate text using prompts and PromptTemplate to interact with the LLMs. To write prompts, you can either use the Zero-shot or Few-shot approach. LangChain provides methods to do both efficiently and PromptTemplate to write dynamic prompts.
Let’s see how it works below.
Running Prompts
In this article, we are going to use the OpenAI LLM. Getting your API KEY for access from the AI provider is essential. We have an article here on how to obtain the credentials.
Install the packages
!pip install langchain
!pip install -qU openaiImport the libraries and set your API Key in an environment variable.
import os
os.environ['OPENAI_API_KEY'] = 'OPENAI_API_KEY'
from langchain.llms import OpenAI
from langchain import PromptTemplate, LLMChain
In this case, we write prompts with no examples by simply telling the model what to do.
davinci = OpenAI(model_name='text-davinci-003')
davinci("I am building an adventure game. Generate the following;" +
"Name, Genre, and Game's story")'\n\nName: "Fantasy Quest"\n\nGenre: Fantasy Role-Playing\n\nGame\'s Story:
You are a brave adventurer who is called upon to save the kingdom from an
evil wizard. As you embark on your journey, you will face many challenges
and obstacles along the way. You must use your wits and skills to
overcome these obstacles and save the kingdom from the wizard\'s dark magic.
Along the way, you will meet strange creatures and make powerful allies who can
help you in your quest. You must explore the land, fight fierce enemies,
solve puzzles, and ultimately find the wizard and put an end to his evil ways.
The fate of the kingdom lies in your hands. Will you be able to save them?'Prompt Engineering
Prompt engineering unlocks the power of prompts in LLM by providing the model with additional context. A good prompt contains instructions and/or examples that give the model the extra help it needs in order to produce a better answer. LangChain has built-in classes to support Prompt Engineering. We can get the LLM to learn more knowledge at inference time with Prompt Engineering, thus optimizing its source knowledge, i.e knowledge provided via input prompts.
PromptTemplate is provided by LangChain, and LangChain allows users to generate prompts for different tasks using it, as well as giving them the capability to construct custom templates.
Here is an example of a Video Game Concept Generator
template = """
Use the example below to write a description of the game's concept and
gameplay metacritic score.
Title: New World
Genre: MMORPG, PvP, Massive Multiplayer, Adventure
Description: Explore a thrilling, open-world MMO filled with danger and
opportunity where you'll forge a new destiny for yourself as an adventurer
shipwrecked on the supernatural island of Aeternum.
Metacritic Score: 10/10
Title: Fallout 76
Genre: Dark Comedy, RPG, Open World, Multiplayer
Description: Fallout Worlds brings unique adventures in
Appalachia with rotating Public Worlds and grants players the
tools to build their own player-created Custom Worlds.
Metacritic Score: 5/10
Title: {query}
Genre: """
prompt_template = PromptTemplate(
input_variables=["query"],
template=template
)Print prediction
print(davinci(prompt_template.format(query="Mantium Party")))
"""
Party, Family, Local Multiplayer
Description: Gather your friends and family around the
TV and play a variety of fun and competitive mini-games in
Mantium Party. The creators designed this party game to offer a
variety of challenges for any occasion, from family reunions
to friends get-togethers. Choose from over 50 mini-games
that test your reflexes, strategy and luck in a variety of
challenging, exciting and sometimes hilariously unexpected
ways.
Metacritic Score: 8/10
"""Prompt engineering gets better with the LangChain FewShotPromptTemplate class that allows the creation of prompt templates with a few shot examples. Depending on the size of examples, we stand the risk of increasing the cost of preprocessing tokens with large example sets. So, the class supports ExampleSelector objects to filter through example sets. ExampleSelector could be custom-generated or created using SemanticSimilarityExampleSelector class. It selects a few shot examples by using an embedding model to determine the similarity between the input and the few shot examples. It also uses a vector store to perform store embeddings to perform the nearest neighbor search.
Another great feature that LangChain supports is Prompt Serialization. This provides the ability to store prompts as files(JSON/YAML), making it easy to share, store and work with multiple versions of prompts. The framework gives you the option of keeping everything in a single file or dividing up individual components, such as templates, examples, and reusable components, into other files and referencing them. Furthermore, LangChain makes it simple to load any kind of prompt by having a single entry point for loading prompts from the disk.
Chains and Components of LangChain
We’ve considered how to use LLM in isolation in the previous section. Now, let’s examine LangChain’s feature that allows chaining multiple LLMs together to achieve much more complex builds.
The components of a chain are: Prompts, LLMs, Utils – which LangChain considers primitives – and other chains. The components are also known as Links.
A simple chain could represent a run for the LLM to generate text. The complexity increases as the chain performs more tasks such as making Web requests and processing the results with LLM.
An example of a potential chain takes user input, formats it with PromptTemplate, and passes the response to the LLM.
Using the template that we created above, we can have a simple chain as shown below to generate a game concept for an “AI Story”.
from langchain.chains import LLMChain
chain = LLMChain(llm=davinci, prompt=prompt_template)
# Run the chain.
print(chain.run("AI Story"))
"""
Action-Adventure, Puzzle, Sci-Fi
Description: AI Story is an action-adventure game that tells
the story of an AI who is trying to discover the mysteries of its world.
Players must solve puzzles, battle enemies, and explore the world in order to
uncover the secrets of the AI.
Metacritic Score: 8/10
"""Creating a simple chain is the starting point for doing much more complex things with chaining.
More Chains
To move further, LangChain supports three types of chains to build end-to-end applications;
- Generic Chains
- Utility Chains
- Asynchronous Chains
Generic chains
Chains that are meant to help build other chains, and not serve a purpose themselves, are called generic chains. Think of them as constructs.
Examples are; LLMChain, TransformationChain, and SequentialChain.
Utility Chains
Developers use these chains to build applications that interact with the LLM to perform an action. Remember the limitations that we highlighted above, You can use LangChain’s utility chains to extend the LLM’s capability and solve these limitations.
An example is LangChain’s LLMRequestsChain – a utility chain that uses the request library to get HTML results from a URL and then uses an LLM to parse results.
With this chain, we can run a direct internet search of our query and use an LLM to format the responses.
Take a look at the example below where we run a google search to find recent information on a topic, and get the LLM to return a formatted response.
from langchain.llms import OpenAI
from langchain.chains import LLMRequestsChain, LLMChain
from langchain.prompts import PromptTemplate
template = """
Format the response from Google by extracting the answer to {query}.
Extract the {requests_result} from the raw search result.
Provide more information in the {requests_result}
Your answer is:
>>> {requests_result} <<<
Extracted:"""
PROMPT = PromptTemplate(
input_variables=["query", "requests_result"],
template=template,
)
chain = LLMRequestsChain(llm_chain = LLMChain(llm=davinci, prompt=PROMPT))question = "What is the story of the recent Twitter take over ?"
inputs = {
"query": question,
"url": "https://www.google.com/search?q=" + question.replace(" ", "+")
}
chain(inputs)
"""
{'query': 'What is the story of the recent Twitter take over ?',
'url': 'https://www.google.com/search?q=What+is+the+story+of+the+recent+Twitter+take+over+?',
'output': '\nElon Musk initiated an acquisition of American social
media company Twitter, Inc. on April 14, 2022, and concluded it on
October 27, 2022. After a seven-month-long saga of petulant tweets,
accusations and legal issues, Elon Musk completed a forty-four-billion-dollar
purchase of Twitter, which he and a group of investors are financing.
The takeover came with changes to the platform, such as paid Twitter verification,
and the introduction of Twitter Blue iOS update.'}
"""LangChain supports more utility chains to interact with an LLMChain, examples are LLMMath, SQLDatabaseChain, API Chain, etc. Additionally, there is support for Async API Chain for asynchronous calls of LLMs.
Data Retrieval and Augmented Generation.
One of the shortcomings of LLMs can be seen in Knowledge retrieval. The ability to access and precisely manipulate external knowledge is still limited for LLMs. Although, a solution might be referencing data by inserting it as context in the model prompt or fine-tuning a model. However, each method has significant drawbacks, as shown in the table below.
| Context-based | Fine-tuning |
| Limited context size | Limited context size & Time-Consuming |
| Longer processing times | Limited external data sources or training data. |
| Expensive API costs | Lack of best fine-tuning practices |
The solution to the drawbacks was discussed in – i) Retrieval-Augmented Generation and ii) Retrieval-Augmented Language Model Pre-Training. It involves retrieving relevant data and augmenting the data with the context in the LLM prompt input. In subsequent sections, we are going to talk about Haystack, and how the open-source tool utilizes concepts of document retrieval to solve a wide range of NLP applications. For now, let’s examine LangChain’s approach called Data Augmented Generation, and the modules and classes involved. It involves two steps; Fetching and Augmenting.
Fetching
LangChain supports classes and modules to get data for different NLP applications such as summarization, question answering, etc. We will examine a few of these modules below;
A. Document Loaders
Loading your own data, and integrating them with LLM might be a good step in building language applications. It can sometimes be tedious and difficult to achieve; we call this “Step One” at Mantium.
LangChain uses Unstructured – a Python package to load files of types for use with LLMs. There are over 20 loaders that LangChain supports, these loaders allow you to bring data from different sources into LangChain. Here is a guide on how to work with any of them. Note that LangChain also has a Loader base class to load documents using a load method that returns Document objects.
B. Indexes
Indexes are structures that help organize documents for efficient retrieval by Language Models (LLMs). They allow LLMs to easily search and find relevant information within large collections of documents. There are various types of indexes, such as vector databases, that can be used to store and retrieve information. Indexes are essential for applications that involve searching large amounts of data, such as search engines, recommendation systems, and chatbots. By using indexes, LLMs can quickly find and present the most relevant information to users, improving the overall user experience.
They provide three classes that support use cases that require indexing.
1. Text Splitting
Text splitting into chunk sizes is a process of breaking down long pieces of text into smaller, semantically meaningful chunks, often sentences. This process is important in information and document retrieval for large language models as it allows for the efficient processing of large amounts of text. The LangChain Text Splitter works by combining small chunks into larger ones until a certain size is reached. Once that size is reached, the chunk becomes its own piece of text, and a new chunk is created with some overlap to maintain context between chunks. The Text Splitter can be customized based on how the text is split and how the chunk size is measured. Examples of the Text Splitter methods are; Character Text Splitting, tiktoken (OpenAI) Length Function, NLTK Text Splitter, etc.
2. Embeddings
LangChain embedding classes are wrappers around embedding models. The classes interface with the embedding providers and return a list of floats – embeddings. Vectors are created using embeddings. If you don’t know what embedding is, read our article here. LangChain supports providers and frameworks such as OpenAI, Cohere, HuggingFace, Tensorflow, etc. Depending on the embedding providers, LangChain base class supports two methods for embeddings – embed_documents and embed_query for embedding the documents, and document queries respectively.
3. Vector Stores
Now that vectors have been created, how do you store them? LangChain provides quite a number of vector stores to store vectors created during the embeddings. They support the following vector stores; Chroma, FAISS, Elastic Search, Milvus, Pinecone, Qdrant, and Weaviate.
Augmenting
Augmenting is simply the process of passing the fetched data to the LLM as context via prompts. This is useful in a number of use cases such as Question-Answering, Summarization, etc. Recall that we covered chains, LangChain designed chains to work with documents, and these chains are methods used in augmenting.
Below is a table that describes these methods;
| Method | Description | Pros | Cons | Example |
| Stuffing | All relevant data is included in the prompt as context. | Makes a single call to the LLM | Large documents or many data pieces may exceed LLM’s context length. | StuffDocumentsChain in LangChain |
| Map Reduce | Initial prompt on each data chunk, followed by combining outputs of different prompts. | – Can handle more data and scale. – Independent calls to LLM can be parallelized. | Requires more LLM calls than Stuffing. | MapReduceDocumentsChain in LangChain |
| Refine | Initial prompt on first chunk of data, refining output based on each subsequent document | Can pull in more relevant context than Map Reduce. | Requires more calls that cannot be parallelized and may have dependencies on document order. | RefineDocumentsChain in LangChain |
| Map-Rerank | Initial prompt on each chunk of data with a score for answer certainty. Responses ranked, and highest score returned. | Requires fewer LLM calls than Map Reduce. | Cannot combine information between documents. Best for simple answers in a single document. | MapRerankDocumentsChain in LangChain |
Example – Build a QA System with LangChain
Let’s use all that we’ve learned so far to build a Question-Answering system on the Earnings Call document for three companies. The system takes questions and returns answers based on the data supplied. Install the Chroma package – Chroma is an open-source tool that provides a vector store and embedding database that can run seamlessly in LangChain.
!pip install chromadbImport libraries
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain import OpenAI, VectorDBQALoad the Earning Calls text file using LangChain’s Document Loader method.
from langchain.document_loaders import TextLoader
loader = TextLoader('earnings_call.txt')
documents = loader.load()Split the text data into chunks
text_splitter = CharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
texts = text_splitter.split_documents(documents)Create embeddings using OpenAI, and store the embeddings in Chroma DB
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_documents(texts, embeddings)
"""
Running Chroma using direct local API.
Using DuckDB in-memory for database. Data will be transient.
"""Create a VectorBDQA Chain
Notice that we are using the Stuffing augmenting method – chain_type="stuff" – to pass all the text data in the prompts.
qa = VectorDBQA.from_chain_type(llm=OpenAI(), chain_type="stuff", vectorstore=docsearch)QA
qa("How many companies do we have their earnings call ?")
"""
{'query': 'How many companies do we have their earnings call ?',
'result': " We have three companies' earnings calls: S&P Global (SPGI),
EOG Resources (EOG) and Main Street Capital (MAIN)."}
"""qa("Generate earnings call summary for S&P ")
"""
{'query': 'Generate earnings call summary for S&P ',
'result': ' S&P Global reported strong second quarter of 2022 earnings
results with year-over-year revenue growth of 15.6%.
They also announced a $1.25 billion share buyback program and
increased the dividend by 10%.
Doug Peterson, President, and CEO, attributed the success to the
combined efforts of the team and stated that the company is stronger,
more resilient, more diversified, and better positioned than ever.'}
"""Agents
This is the last area of LangChain that this article will talk about.
What is an Agent?
An agent is what LangChain uses to delegate actions to LLMs. Agents use an LLM to determine which actions to take and in what order. Remember the example where ChatGPT didn’t have results about today’s weather? We can use agents to ask the LLM to search the internet or query the weather API for information on how to answer the question.
To create an agent, there are certain parameters that need to be considered. First is the Tool, which is a function that performs a specific duty such as a Google search, database lookup, Python REPL, or other chains. The second parameter is the LLM, which powers the agent, and the third is the agent itself. The agent should be a string that references a support agent class, which is currently limited to the standard supported agents.
Haystack
In the previous sections, we talked about LangChain’s features, and how to utilize them to build language applications. While LangChain supports quite a lot of different use cases in NLP, we are going to talk about another open-source tool called Haystack that is used in building large-scale search systems. Information retrieval which is an area of focus for Haystack, and is also an area of overlap with LangChain. Haystack also supports prompting to achieve summarization, question-answering, translation, etc.
What is Haystack?
Haystack is a versatile open-source Python framework that provides developers with a toolkit to create powerful search systems that can efficiently handle large document collections. Whether you’re building a search engine for a web application, an e-commerce platform, or a knowledge management system, Haystack makes it easy to integrate advanced search capabilities into your project.
We are going to examine the concepts in Haystack and how they power search applications.
Haystack’s Data Structures
Before we talk about components and pipelines. Let’s talk about Haystack’s core data structures, which are Documents, Answers, and Labels. The table below describes each class of data structures.
| Short Description | How it’s returned | Method | |
| Documents | Contains information like text, tables, or images with an id and metadata. May also contain model confidence scores. | Retriever and Ranker nodes or pipelines containing those nodes. | DocumentStore.write_documents() |
| Answers | Contains prediction information like answer string, model confidence score, context around answer, and metadata. | Reader and Generator nodes or pipelines containing those nodes. | Reader and Generator nodes or pipelines |
| Labels | Contains information relevant to one document retrieval or question-answering annotation. Used for evaluation purposes. | DocumentStore.get_all_labels() method is called on DocumentStore or supplied in Evaluation Pipelines. | DocumentStore.get_all_labels() |
Pipelines in Haystack
It is important to understand the concept of pipeline in Haystack, as everything about building search applications is based on a Pipeline. It allows you to construct directed acyclic graphs (DAGs) with a retriever, reader, and generator models as nodes. The querying pipeline starts with a query node that takes in a user query and uses the information stored in a DocumentStore to retrieve the best-matching documents. Meanwhile, the indexing pipeline converts files into Haystack Documents and preprocesses them before saving them to the DocumentStore.
Haystack makes it really easy to build applications with its Ready-made pipelines
Components in Haystack – Nodes
Just like the components in LangChain are made up of primitives and chains, Haystack’s components similarly are the building blocks of a pipeline. Although nodes are sometimes called components, they require a pipeline to put them together. They are chained together using a Pipeline, where the output of a previous component is the input of the next component.
Let’s examine each component and how they function together in building NLP systems.
LLMs & Prompt
Haystack offers nodes, called PromptNode, to use prompts to perform different NLP tasks. By default, it uses the google/flan-t5-base model, but just like LangChain, you can use other LLM models by specifying the name and API key. See example;
Install Haystack package
%%bash
pip install --upgrade pip
pip install farm-haystack[colab]In this example, we set the model to OpenAI’s davinci model.
from haystack.nodes import PromptModel, PromptNode
openai_api_key = "sk-key"
open_ai_prompt_model = PromptModel(model_name_or_path="text-davinci-003", api_key=openai_api_key)
# Make PromptNode use the model:
pn_open_ai = PromptNode(open_ai_prompt_model)
pn_open_ai("Who is the CEO of Apple?")
"""
['The current CEO of Apple is Tim Cook.']
"""Templates in Haystack
For better results, you can use the many templates offered for different NLP tasks in Haystack. With the PromptNode, you can specify the template name, and pass additional variables, such as documents or questions into the Node.
There is great flexibility in using templates in Haystack. You can add your own template, and even if the name of the template isn’t provided the node tries to guess what task it should perform.
Data Processing
How is data processing done in Haystack?
Haystack is a powerful tool for handling data that comes with various components. These components are grouped into the data handling components and perform various operations on data such as crawling, preprocessing, and classifying them. The available components for data handling are Crawler, DocumentClassifier, EntityExtractor, FileTypeClassifier, FileConverter, and PreProcessor.
The Crawler is a component that scrapes text from a website and creates a Document object, which is saved to a JSON file. This component is used at the beginning of an indexing pipeline, and it can be used to add the contents of a website to files for use in search.
The DocumentClassifier component classifies Documents by attaching metadata to them. One can use it in a pipeline or on its own, and people commonly use it for sentiment analysis. The EntityExtractor node extracts predefined entities from a piece of text, and it is used for named entity extraction (NER).
The FileTypeClassifier distinguishes between text, PDF, Markdown, Docx, and HTML files and routes them to the appropriate FileConverter in an indexing pipeline. The FileConverter, on the other hand, extracts text from files in different formats and casts it into the unified Document format. There are several available converters for different file formats, such as PDFs, images, DOCX files, and more.
Lastly, the PreProcessor component performs several operations on documents such as cleaning and splitting text These components work together to enable effective and efficient handling of data in Haystack.
Document Stores
How does Haystack store documents?
Haystack document stores provide a simple and efficient way to store and retrieve large volumes of text-based data. One of the key advantages of using Haystack’s document store is the ability to use it in conjunction with a retriever, which allows you to easily fetch documents at query time.
When choosing a document store, it is important to consider factors such as the size of your data set, the complexity of your queries, and the technical environment in which your project will be deployed. For example, Elasticsearch is a popular choice for sparse retrieval with many tuning options, while FAISS is a fast and accurate option for dense retrieval. OpenSearch is a fully open-source option that is essentially the same as Elasticsearch, but with more support for vector similarity comparisons and approximate nearest neighbors algorithms.
In addition to choosing the right document store, it is also important to consider how to optimize retrieval speed. Approximate nearest neighbors (ANN) search is one way to significantly improve retrieval speed, though there is a slight tradeoff in retrieval accuracy. Haystack supports ANN in several document stores, including FAISS, Opensearch, Milvus, Weaviate, and Pinecone. ANN is particularly useful when working with large collections of documents, and it can be turned on or off depending on the needs of your project. Overall, choosing the right document store and optimizing retrieval speed can make a significant difference in the efficiency and accuracy of your data retrieval pipeline.
Semantic Search and Question-Answering
Above we called out different limitations with LLMs, especially in information retrieval. Haystack makes it possible to build scalable search systems. Let’s examine the components involved in building search systems with Haystack.
If you are new to Question-Answering, we recommend that you read our articles listed below;
One of the core components of Haystack is the Retriever, which performs document retrieval by sweeping through a DocumentStore and returning a set of relevant documents based on a given query. Haystack has tested retrievers on various modalities and can be combined with a Reader to quickly sift out irrelevant documents and provide an answer to the query based on the set of relevant documents retrieved. However, the retriever is not sensitive to word order, and to offset this weakness, a Ranker can be used to have a better-sorted list of relevant documents.
Another core component of Haystack is the Reader, which takes a question and a set of Documents as input and returns an answer by selecting a text span within the Documents. Readers are built on the latest transformer-based language models and are strong in their grasp of semantics and sensitive to syntactic structure. To convert a language model into a reader model, a question-answering prediction head is added on top of the language model. The readers in Haystack contain all the components of end-to-end, open-domain QA systems, including loading of model weights, tokenization, embedding computation, span prediction, and candidate aggregation. However, a GPU is required to run the Reader quickly in Haystack.
Haystack offers a GenerativeQAPipeline that combines the Retriever with an AnswerGenerator component to provide answers to questions. The Generator uses the model’s trained knowledge and the external knowledge provided by the Retriever’s output to generate more worded answers.
Example – Build a Generative QA system with Haystack using the GenerativeQAPipeline
We are going to use the same earnings call document.
Install the Haystack package
%%bash
pip install --upgrade pip
pip install farm-haystack[colab]import logging
logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
logging.getLogger("haystack").setLevel(logging.INFO)Here we are going to use ElasticsearchDocumentStore that connects to a running Elasticsearch service to store the document.
%%bash
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.2-linux-x86_64.tar.gz -q
tar -xzf elasticsearch-7.9.2-linux-x86_64.tar.gz
chown -R daemon:daemon elasticsearch-7.9.2Start the server.
%%bash --bg
sudo -u daemon -- elasticsearch-7.9.2/bin/elasticsearchimport os
from haystack.document_stores import ElasticsearchDocumentStore
# Get the host where Elasticsearch is running, default to localhost
host = os.environ.get("ELASTICSEARCH_HOST", "localhost")
document_store = ElasticsearchDocumentStore(
host=host,
username="",
password="",
index="document"
)Here, we are going to add the documents to DocumentStore. We will use an indexing pipeline to convert the files into Document objects, and write them to the ElasticsearchDocumentStore
doc_dir = "/content/earnings_call"
from haystack import Pipeline
from haystack.nodes import TextConverter, PreProcessor
indexing_pipeline = Pipeline()
text_converter = TextConverter()
preprocessor = PreProcessor(
clean_whitespace=True,
clean_header_footer=True,
clean_empty_lines=True,
split_by="word",
split_length=200,
split_overlap=20,
split_respect_sentence_boundary=True,
)Just like we learned above, we used the TextConverter , to convert txt files into Haystack Document objecrts, and used the PreProcessor component for data preprocessing.
Indexing Pipelines
indexing_pipeline.add_node(component=text_converter, name="TextConverter", inputs=["File"])
indexing_pipeline.add_node(component=preprocessor, name="PreProcessor", inputs=["TextConverter"])
indexing_pipeline.add_node(component=document_store, name="DocumentStore", inputs=["PreProcessor"])files_to_index = [doc_dir + "/" + f for f in os.listdir(doc_dir)]
indexing_pipeline.run_batch(file_paths=files_to_index)Initialize the Retriever
from haystack.nodes import BM25Retriever
retriever = BM25Retriever(document_store=document_store)
Initialize the generator – OpenAI
from haystack.nodes import OpenAIAnswerGenerator
MY_API_KEY= "sk-key"
generator = OpenAIAnswerGenerator(api_key=MY_API_KEY, max_tokens=600, temperature=0.5, presence_penalty=0, frequency_penalty=0)
Use the GenerativeQAPipeline
from haystack.pipelines import GenerativeQAPipeline
pipeline = GenerativeQAPipeline(generator=generator, retriever=retriever)
result = pipeline.run(query='Generate earnings call summary for S&P', params={"Retriever": {"top_k": 5}})
pprint(result)
{'answer': "S&P released its earnings for the second quarter of fiscal 2022.
The company reported adjusted earnings of $0.68 per share,
beating the Thomson Reuters consensus estimate of $0.65 by $0.03.
The company's revenue also met expectations,
increasing by 5.9% year-over-year to $2.2 billion.
The company's earnings were negatively impacted by the global
credit market conditions, but the company's integration management
team is maintaining fiscal and operational discipline in
controlling what can be controlled.", 'type': 'generative'The result
{'answer': "S&P released its earnings for the second quarter of fiscal 2022.
The company reported adjusted earnings of $0.68 per share,
beating the Thomson Reuters consensus estimate of $0.65 by $0.03.
The company's revenue also met expectations,
increasing by 5.9% year-over-year to $2.2 billion.
The company's earnings were negatively impacted by the global
credit market conditions, but the company's integration management
team is maintaining fiscal and operational discipline in
controlling what can be controlled.", 'type': 'generative'Conclusion
Both LangChain and Haystack support quite a lot of NLP use cases. They have a unique approach to extending the use of LLMs to build real-world applications.
Haystack is useful in building large-scale search systems, question-answering, summarization, and conversational AI. LangChain also supports these use cases and interaction with external apps.
LangChain stands out in its support of combining LLMs with other technologies to build powerful applications through Agents to delegate actions to LLMs. Haystack currently has this on its roadmap, and they are working on adding Agent components just like LangChain to components. LangChain and Haystack offer different approaches to building language applications.
Step one with Mantium
In this article, we explained what LangChain and Haystack offer to address the limitation of using LLM to build language applications. We examined the building blocks of each library, and how they come together to build applications. The takeaway here is that getting data to build applications is still a big challenge, and manipulating external knowledge is still limited for LLMs.
It is why at Mantium, we are working on the fastest way to achieve “Step One” in the AI pipeline – which is getting data. With our solution, you can now create applications by leveraging a combination of language models that have a foundation in your internal knowledge sources. You can aggregate data from multiple sources, sync data to ensure recent information, create transformations in the format that you need, and ship datasets to where they are needed or stored. Visit our website to learn more about what we are building.
References
- LangChain Documentation
- Haystack Documentation
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- Knowledge Retrieval Architecture for LLM’s (2023)
Follow us



Subscribe to the Mantium Blog
SubscribeMost recent posts

Enjoy what you're reading?
Subscribe to our blog to keep up on the latest news, releases, thought leadership, and more.