
Introduction
In this article, we will learn how to build a question-answering (QA) system with the Haystack model using text data from our Developer portal as the knowledge base. Let’s see how we can improve the current search capabilities of the portal with this QA system.
Suppose you need to become more familiar with question answering. We recommend you read our article on “Understanding Question Answering,” where we introduce the concept and explain some prerequisite knowledge that you need to follow this tutorial effectively.
Current Search Results
This tutorial aims to build a QA pipeline that returns answers better than the current search capabilities of the Mantium’s developer portal (readme’s search).
Below are images of search results for two questions. Notice that we didn’t get any text results, instead we got possible articles that might answer the queries – not helpful.
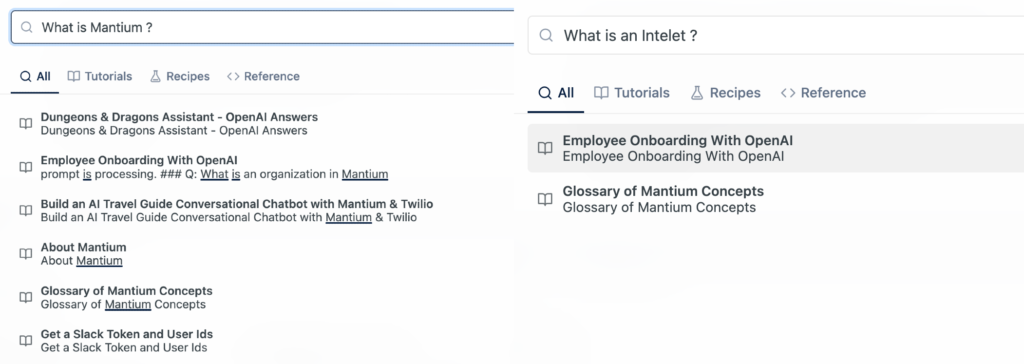
Let’s see the answers that the Haystack QA pipeline returns. Will the answers be better or worse?
Read along to find out.
Documents
The first task of this tutorial is to get the data from our knowledge base. In this case, a knowledge base is where we want to draw the information from, such as websites, wikis, internal documents, etc.
We downloaded the articles we have on the Mantium developer’s portal, a site that readme.io manages. The articles are the documents we will store in a document store, and Haystack finds answers to queries within the documents.
Data Cleaning Walkthrough
After downloading the articles, we have many markdown files that need cleaning and preprocessing.
A straightforward approach will be to read the text lines from the markdown files, remove the unwanted characters with a custom function, convert markdown syntax to HTML and use Beautifulsoup – a Python package for parsing HTML files – to remove HTML tags from the documents.
We converted to HTML after cleaning with the custom function because the custom function will only handle the removal of ReadMe’s proprietary “Magic blocks”; see the image below for an example.
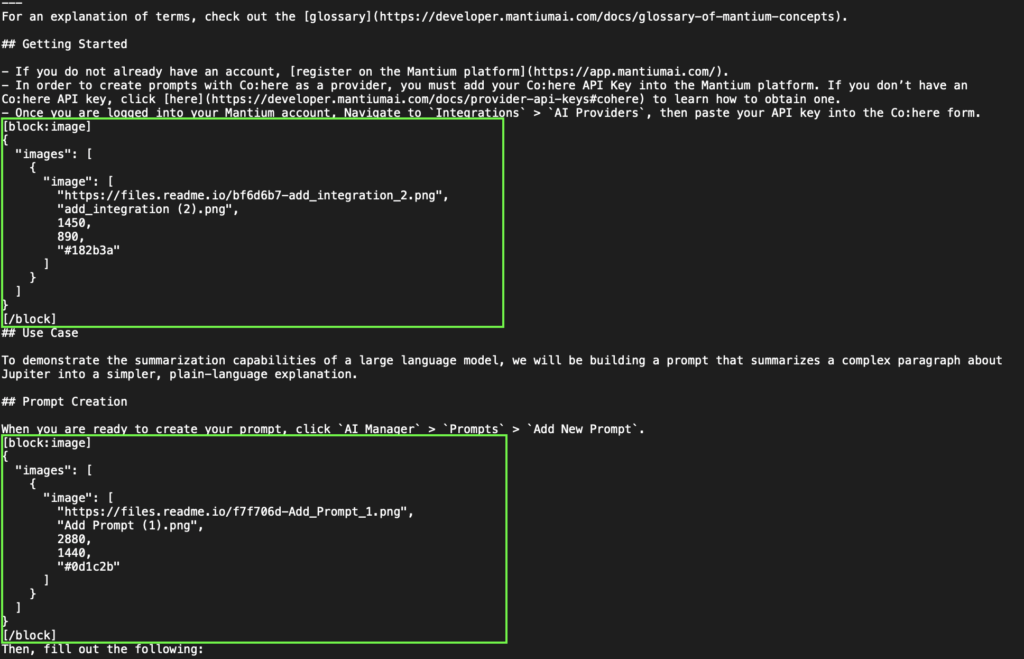
Then, converting from markdown to HTML changes the remaining markdown elements to HTML tags, making it possible to leverage the power of Beautifulsoup for the rest of the data cleaning process (remove unwanted HTML tags).
QA Code Walkthrough
You can use Google Colab environment to write the code.
Import Libraries
The code snippet below shows the import statement of the libraries and adds the directory path where we have the markdown files.
import markdown
import os
from bs4 import BeautifulSoup
import json
directory = '<markdown files folder path>'Remove Magic Blocks
The function below removes Readme’s proprietary magic blocks ( [block:]) and the elements within the block. The data is not helpful for this QA system.
# function to remove magic blocks
def remove_magic_block(text):
is_within_block = False
for i, line in enumerate(text):
if is_within_block:
text[i - 1] = None
text[i] = None
if line.startswith("[/block]") or line.startswith("[block:"):
is_within_block = not is_within_block
return list(filter(None, text))Remove HTML Tags
The function below removes HTML tags using Beautifulsoup.
# function to remove HTML tags after markdown conversion
def remove_tags(html):
soup = BeautifulSoup(html, "html.parser")
for data in soup(['style', 'script']):
data.decompose()
return ' '.join(soup.stripped_strings)The Cleaning Process
After writing the remove_magic_block and remove_tags function, we can call the function to clean the text data.
all_blogs = list()
count = 0
for filename in os.listdir(directory):
with open(os.path.join(directory, filename), 'r') as f:
text = f.readlines()
text_new = remove_magic_block(text)
text_new = ''.join(text_new)
html = markdown.markdown(text_new)
untag_text = remove_tags(html)
all_blogs.append({"content": untag_text, "meta": {"name"+str(count): "file"+str(count)}})
count += 1
f.close()In the code snippet above, we are reading all lines in the file as a list where each line is an item in the list object. Then, we can call the remove_magic_block function to remove the magic blocks, convert from markdown syntax to HTML, and remove the tags.
The last part of the code snippet shows that we are appending the text data alongside the “content” and “meta” keys in the dictionary – why?
The reason is that the format for writing into a document store Haystack DocumentStore is a list of dictionaries with the following key-value pairs format.
{
'content': "<DOCUMENT_TEXT_HERE>",
'meta': {'name': "<DOCUMENT_NAME_HERE>", ...}
}Write Clean Text to a File
We already have the text in the right format, the next thing is to write it to a JSONL file.
with open('qafile.jsonl', 'w') as outfile:
for entry in all_blogs:
json.dump(entry, outfile)
outfile.write("\n")
outfile.close()This is the end of the cleaning process. Up next, we are going to build the QA pipeline with Haystack.
Build QA Pipeline
Now we have clean data to work with, let’s build the QA pipeline.
Setting up the environment.
Note that this tutorial assumes that you are using Google Colab notebook.
1. Select GPU runtime
In the Google Colab notebook, enable the GPU runtime by navigating to “Runtime” at the top nav bar, select “Change runtime type”, and select “GPU” Hardware accelerator.
2. Install Haystack
Using the command below, you can install the latest version of Haystack.
%%bash
pip install --upgrade pip
pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]Document Store
We will pass the documents to Haystack’s DocumentStore. The DocumentStore is an ElasticsearchDocumentStore – a Haystack implementation of Elasticsearch.
Elasticsearch is a search engine and analytics tool powered by a schema-free document database. In Elasticsearch, we store data as schema-less documents within indices. So you can think of a single index as a document in your dataset.
With Haystack, we can easily work with Elasticsearch and store our cleaned documents in a DocumentStore. The code snippets below show the next steps in writing documents to the DocumentStore.
A. Import Libraries
import logging
import json
import time
import osB. Setup Elasticsearch
Logging
logging.basicConfig(format="%(levelname)s - %(name)s - %(message)s", level=logging.WARNING)
logging.getLogger("haystack").setLevel(logging.INFO)Start an Elasticsearch Server
%%bash
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.2-linux-x86_64.tar.gz -q
tar -xzf elasticsearch-7.9.2-linux-x86_64.tar.gz
chown -R daemon:daemon elasticsearch-7.9.2%%bash --bg
sudo -u daemon -- elasticsearch-7.9.2/bin/elasticsearchC. Create Document Store Instance
Here, we are going to create an instance of the Document Store.
from haystack.document_stores import ElasticsearchDocumentStore
time.sleep(30)
host = os.environ.get("ELASTICSEARCH_HOST", "localhost")
document_store = ElasticsearchDocumentStore(host=host, username="", password="", index="document")The server details include the host as localhost. We don’t need a username, and password, so we set them to an empty string. The index is the document we will write to the document store.
D. Write to Document Store
Here we are going to write the dicts from our JSON file to the document store following the code block below.
f = open('outputfile.json')
data = json.load(f)
f.close()
# print a part of the data
print(data[1:3])# write the dicts containing documents to our DB.
document_store.write_documents(data)QA Pipeline
In the previous tutorial, we talked about different components of a QA system. You can read here for more information.
Retriever – Reader (QA System)
The retriever model we will use here is the Elasticsearch’s default BM25 algorithm. The BM25 is a bag-of-words retrieval algorithm that ranks a set of documents according to the query keywords that exist in each document, regardless of where in the text they appear. It gives better results compared to earlier TF-IDF-based scoring algorithms.
The Reader carefully examines the texts that retrievers have returned and selects the top-k solutions.
from haystack.nodes import BM25Retriever
from haystack.pipelines import ExtractiveQAPipeline
from haystack.nodes import FARMReader
retriever = BM25Retriever(document_store=document_store)
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2", use_gpu=True)
pipe = ExtractiveQAPipeline(reader, retriever)Run the Pipeline
Above, we used the ExtractiveQAPipeline that combines a retriever and a reader to answer our questions. We will ask the question, “What is an Intelet ?”, we expect to get an answer that answers the question from the documents (articles from the Mantium portal).
Question 1
We will ask the question, “What is an Intelet ?”, we expect to get an answer that answers the question from the documents (articles from the Mantium portal).
from pprint import pprint
prediction = pipe.run(
query="What is an Intelet ?", params={"Retriever": {"top_k": 10}, "Reader": {"top_k": 5}}
)
pprint(prediction){'answers': [<Answer {'answer': 'multiple prompts chained together',
'type': 'extractive', 'score': 0.8445422649383545,
'context': 'rch, Completion, Answer, and Classification.
Intelets are multiple prompts chained together. Q: What is a security policy?\nA:
A set of security rules', 'offsets_in_document': [{'start': 3239, 'end': 3272}],
'offsets_in_context': [{'start': 59, 'end': 92}], 'document_id': 'some-long-id', 'meta': {'name5': 'file5'}}>,Question 2
Here we will ask – “What is Mantium ?” Notice below that the context for this answer is from a document that explains what Mantium does.
{'answer': 'enables the AI enthusiasts (personal and professional) to rapidly prototype and share',
'type': 'extractive', 'score': 0.6971570253372192,
'context': 'What does Mantium do?\nA: Mantium enables the AI enthusiasts
(personal and professional) to rapidly prototype and share large language models, solving ',
'offsets_in_document': [{'start': 2151, 'end': 2236}], 'offsets_in_context
: [{'start': 33, 'end': 118}],
'document_id': 'some-long-id', 'meta': {'name5': 'file5'}}>,Retriever-Generator (QA System)
Our previous article described the Retriever-Reader, and Retriever-Generator approaches to QA. The Retriever-Generator approach has a generator model that uses the question, alongside the contexts and its knowledge, to generate answers. An example of a generator model is OpenAI GPT-3.
In this tutorial section, we will implement a GenerativeQAPipeline pipeline and compare the result to the ExtractiveQAPipeline in the previous section.
from haystack.nodes import OpenAIAnswerGenerator
MY_API_KEY= "<your-openai-key>"
generator = OpenAIAnswerGenerator(api_key=MY_API_KEY, max_tokens=500, temperature=0.5, presence_penalty=0, frequency_penalty=0)Code Implementation
In this case, the OpenAI GPT3 model is the generator, and you need the OpenAI Key to initialize the model. If you are not familiar with how to get an OpenAI key, read our tutorial here.
The Pipeline
Similar to the ExtractiveQAPipeline, below is the implementation of how to set up the GenerativeQAPipeline.
from haystack.pipelines import GenerativeQAPipeline
pipeline = GenerativeQAPipeline(generator=generator, retriever=retriever)
result = pipeline.run(query='What is Mantium ?', params={"Retriever": {"top_k": 5}})
pprint(result)Above we use the loaded QA model to generate answers for a query based on the documents it receives.
Question 1
What is an Intelet ?
{'answers': [<Answer {'answer': " An intelet is a group of AI's.",
'type': 'generative', 'score': None,
'context': None, 'offsets_in_document': None, 'offsets_in_context': None, 'document_id': None, 'meta': {'doc_ids': ['some-long-id'], 'doc_scores': [0.6173451890063558], 'content': ['title: "Glossary of Mantium Concepts"Question 2
What is Mantium ?
{'answers': [<Answer {'answer': ' Mantium is a platform that enables users to create and deploy prompts with AI21.', 'type': 'generative', 'score': None, 'context': None, 'offsets_in_document': None, 'offsets_in_context': None, 'document_id': None, 'meta': {'doc_ids': ['some-long-id'], 'doc_scores': [0.5405804190031087], 'content': ['title: "Create Your First Prompt With AI21"Improved Results
| Query | Readme’s result | ExtractiveQAPipeline Answer | GenerativeQAPipeline Answer |
|---|---|---|---|
| What is an Intelet ? | No text result | Multiple prompts chained together | An intelet is a group of AI’s. |
| What is Mantium ? | No text result | Enables the AI enthusiasts (personal and professional) to rapidly prototype and share | Mantium is a platform that enables users to create and deploy prompts with AI21. |
Remember that we didn’t get any text results when we used the readme search. The ExtractiveQAPipeline (Retriever-Reader) returned answers to the queries from the documents, while GenerativeQAPipeline (Retriever-Generator) used the generator model to generate the answer using the context and its knowledge. The QA pipelines performed much better than the search results from readme.io.
Conclusion
This tutorial taught us how to clean markdown documents, build QA pipelines and compare different QA approaches. We can see that the QA pipeline with the Haystack model returned better results than the native search capabilities of the Readme platform (the Mantium developer portal).
Follow us



Subscribe to the Mantium Blog
SubscribeMost recent posts

Enjoy what you're reading?
Subscribe to our blog to keep up on the latest news, releases, thought leadership, and more.